The 5 Levers on Your Anthropic Bill (and How to Stack Them Without Double-Counting)
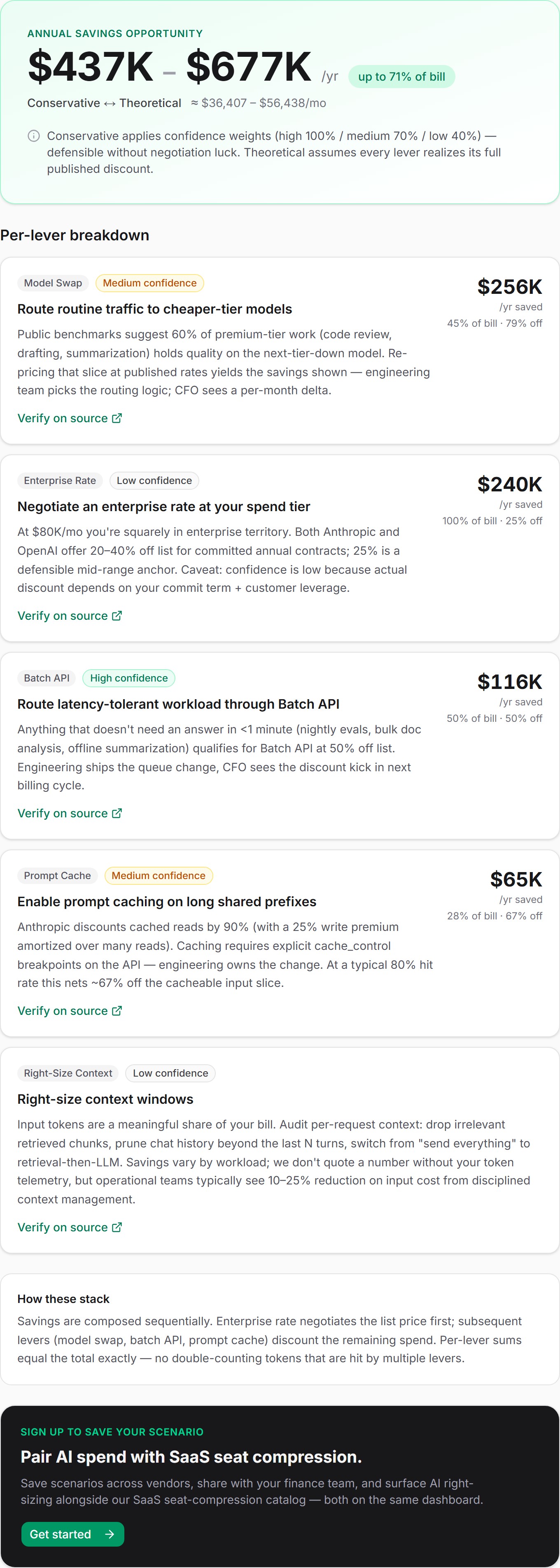
An enterprise with an $80,000-per-month Anthropic bill — 60% Opus, 30% Sonnet, 10% Haiku, mixed workload, no prompt caching, pay-as-you-go — has between $437,000 and $677,000 of annual savings sitting on the table. The wide range is intentional. The conservative number applies confidence weights to every dollar; the theoretical number assumes every lever realizes its full published discount. A CFO presentation that quotes one without the other is either timid or unfalsifiable.
This post walks through the five levers, the source quotes that back each rate, and the sequential-residual stacking math that keeps the total from claiming you can save more than 100% of your bill. Which, embarrassingly, is what additive stacking produced when we first shipped this — 151% in the worst case before code review caught it.
Try the AI Spend calculator — 15 seconds, no signup.
Why this calculator exists
The seat-compression product we ship today answers one question: "how many SaaS seats are you paying for that nobody uses." A year of conversations with CFOs has surfaced a second, parallel question — almost always asked in the same meeting: "what do we do about our Anthropic / OpenAI / Google API bill, which used to be $5K/mo and is now $80K and growing?"
That bill behaves differently from a SaaS seat invoice. Seats are committed quantities you over-bought; token consumption is metered usage you under-optimized. The compression levers are entirely different. But the trust contract is the same as our SaaS catalog: every dollar figure traces to a vendor pricing page URL, every claim carries a literal quote, and the calculator's headline number is bounded by construction so it can't run away to numbers that fail a CFO sanity check.
We covered why anti-fabrication matters for SaaS in the calculator deep-dive. The methodology here is the same shape, applied to a different invoice.
The five levers, in the order they fire
The order matters — sequential-residual stacking is the headline correctness fix and we'll explain why after the lever list. Briefly, each lever operates on the spend remaining after upstream levers have already fired. That's how four levers stay bounded ≤ 100% of the bill instead of overlapping and producing nonsense totals.
Lever 1: Enterprise rate negotiation
Fires first because it discounts list price, which everything downstream uses as a base. Both Anthropic and OpenAI offer committed-spend or annual contracts for customers at sufficient scale. The published claim from Anthropic's enterprise contact page is "Anthropic enterprise plan — custom pricing for committed-spend customers." Real customer reports cluster between 20% and 40% off list. We anchor at 25% as a defensible mid-range and tag the lever confidence: "low" because actual discount depends on commit term, leverage, and how badly your account manager wants to close before quarter-end.
The threshold we use is $50,000/month, per ENTERPRISE_RATE_THRESHOLD_MONTHLY_USD in the rates file. Below that, the lever doesn't apply — vendors won't bother with the procurement conversation. Above it, you should at minimum ask for the meeting.
Applied to $80K/mo: 25% × $80,000 = $20,000/mo, or $240,000/year, against the full bill. Residual after this lever: $60,000/mo.
Lever 2: Model swap
Fires second because it lowers the per-token rate on the residual. Anthropic's pricing page lists Opus 4 at $15 per million input tokens and $75 per million output (sourceUrl: https://www.anthropic.com/pricing). Sonnet 4 lists at $3/$15 — five times cheaper on both axes. Claude 3.5 Haiku is $0.80/$4. The math question is what fraction of premium-tier traffic can move down a tier without meaningful quality loss.
We anchor at 60% of Opus traffic swap-able to Sonnet, and 30% of Sonnet traffic swap-able to Haiku, per the MODEL_SWAP_SHARES constants. These are calibrated against Anthropic's published evals showing Sonnet 4 reaches ~85% of Opus on coding and reasoning benchmarks for routine work. Code review, drafting, summarization, classification — the workloads where you don't need frontier reasoning — are typically swap-able. Frontier reasoning, complex agentic loops, novel research — those stay on the premium model. The lever is tagged confidence: "medium" because the right swap rate depends on your evals, not ours.
For OpenAI customers, the swap chain is GPT-4o → GPT-4o mini (50% of traffic) and o1 → o1-mini (40%). For Google, Gemini 2.5 Pro → Flash (50%). The math is identical — compute blended input/output cost at workload weights, compare cheaper-model blend, only credit savings where the cheaper tier is actually cheaper. The full algorithm is in src/lib/ai-spend/levers.ts, modelSwap.
Applied to the Anthropic example, mixed workload (40% input / 60% output weighting):
- Opus blended cost: $15 × 0.4 + $75 × 0.6 = $51 per million tokens
- Sonnet blended cost: $3 × 0.4 + $15 × 0.6 = $10.20 per million tokens
- Sonnet vs Opus reduction: 1 − $10.20 / $51 = 80%
- 60% of Opus traffic × 60% swap rate = 36% of bill touched at an 80% rate cut
- Sonnet → Haiku reduction similarly ≈ 73% on the 9% of bill that qualifies (30% Sonnet × 30% swap)
- Combined touchedShare ≈ 45% of bill at a saving-weighted ~78% discount
That works out to roughly $21,249/mo realized after the enterprise discount has already chopped the residual. Residual now: about $38,751.
Lever 3: Batch API
Fires third because it time-segregates a share of the post-swap residual. Both Anthropic and OpenAI publish a flat 50% discount on the Batch API. The Anthropic quote, per the pricing page: "Batch API — 50% discount on input + output tokens." The OpenAI quote: "Batch API — 50% off, results within 24 hours." Google offers similar via Vertex Batch Predictions.
This lever is tagged confidence: "high" — it's the most defensible number on the page. The discount is published, the implementation is a queue change, and there's no negotiation involved. The only judgment call is what fraction of your workload tolerates ≤24-hour latency. Anything real-time (chat UI, voice agents, interactive code completion) doesn't qualify. Anything offline (nightly evals, bulk document processing, summarization pipelines that don't need an answer in under one minute) does.
The calculator asks for realtimeShare as a slider — at 50% real-time, half your bill qualifies for batching, and the effective discount is 25% of the residual (0.50 × 0.50).
Applied to the example, assuming 50% real-time: $38,751 × 50% × 50% = $9,688/mo. Residual: about $29,063.
Lever 4: Prompt cache
Fires fourth because it content-segregates the input slice of the post-batch residual. Anthropic's quote: "Prompt caching — 90% discount on cache reads; 25% premium on writes." OpenAI's quote: "Cached input pricing — 50% discount on repeat input tokens." Google's: "Context caching — 75% discount on cached input retrieval."
The vendor asymmetry matters. Anthropic caching requires explicit cache_control breakpoints in the API — engineering has to opt in. OpenAI auto-discounts cached input tokens 50% for any prompt ≥1,024 tokens with no opt-in required. That means an OpenAI customer who answers "no cache" in our calculator may already be getting some of this discount silently — the calculator's reason copy explicitly flags that. We don't double-count what's already in the bill.
The applicability defaults: 70% of input tokens are typically cacheable (the shared system-prompt prefix), at an 80% hit rate at steady state. The net Anthropic savings multiplier on cacheable input is 0.8 × (1 − 0.10) − 0.2 × 0.25 = 0.67 — 67% off the cacheable input slice. For mixed workload (40% input weighting), applicableShare = 0.4 × 0.7 = 0.28. The lever is tagged confidence: "medium" because hit rate varies materially with prompt structure.
Applied to the example: $29,063 × 28% × 67% ≈ $5,452/mo. Residual: roughly $23,611.
Lever 5: Right-size context
Always last, always qualitative, always zero dollars. The lever surfaces as advisory copy rather than a number we can't defend without your token telemetry. The recommendation is mechanical: audit per-request context, drop irrelevant retrieved chunks, prune chat history beyond the last N turns, switch from "send everything" to retrieval-then-LLM patterns. Operations teams typically see 10–25% input-cost reduction from disciplined context management — but we don't bake that into the headline because we can't see your prompts. Engineering owns the action; CFO sees it land in the next billing cycle.
The total: $56,389/mo realized, $676,668/yr theoretical
Sum across the four numeric levers:
| Lever | Monthly | Confidence |
|---|---|---|
| Enterprise rate | $20,000 | low |
| Model swap | $21,249 | medium |
| Batch API | $9,688 | high |
| Prompt cache | $5,452 | medium |
| Total realized | $56,389 | mixed |
Annualized, that's $676,668 — the upper bound of the range in the screenshot. By construction this number is ≤ $80,000 (the monthly bill). It cannot run away to "save more than you spend" because each lever operates on the spend remaining after upstream levers. The arithmetic is in calculateAiSpendSavings in src/lib/ai-spend/calculate.ts.
Why additive stacking is wrong (and how we caught it)
The first version of this calculator added the levers up. Enterprise saves 25%, model swap saves another ~30%, batch saves another ~25%, cache saves another 20% — sum: roughly 100%. Looked fine on paper. Looked wrong on the dev server: a default scenario rendered 116.9% total savings. The worst-case run hit 151%.
The root cause is that the four levers touch overlapping facets of the same tokens. A single Opus token used inside a long shared prefix that runs in a nightly batch job on an enterprise contract is discounted by all four levers. Additive stacking counts that token four times. Sequential-residual stacking counts it once.
Mechanically: the four levers fire in the order enterprise_rate → model_swap → batch_api → prompt_cache (the order in ALL_LEVERS from src/lib/ai-spend/levers.ts). Each operates on the residual spend after upstream levers have already fired. Per-lever realized savings = applicableShare × effectiveDiscount × residual. The orchestrator updates the residual after each lever:
residual = monthlyTotalUsd
for each applying lever:
realized = applicableShare × effectiveDiscount × residual
residual = max(0, residual − realized)
By construction, the per-lever sum equals total ≤ monthlyTotalUsd. We added five regression tests to pin the invariant.
Reordering changes per-lever attribution but not total savings — within float precision. The order we picked has a finance logic: negotiate the unit rate first (enterprise), then optimize the per-token cost (model swap), then time-segregate (batch), then content-segregate (cache). It's the order a procurement-savvy finance team would walk a vendor through.
This is the methodological claim we'd push back on if a competitor FinOps tool — Vantage, CloudZero, Spendflo's AI module — shows you a stacked-savings number without explaining how the levers compose. If they're adding, they're producing impossible totals on some non-trivial fraction of their customer base. If they're sequencing, they should be able to tell you the order.
Conservative vs. theoretical: the range hero
The screenshot reads $437K – $677K/yr · Conservative ↔ Theoretical. The theoretical number is the $676,668 we just computed — sum of per-lever realized savings, no quality adjustment. The conservative number applies a confidence weight to each lever before summing:
- High confidence × 1.0
- Medium × 0.7
- Low × 0.4
These weights are pinned in CONFIDENCE_WEIGHTS (src/lib/ai-spend/types.ts) and calculate.test.ts. The conservative aggregation for the same example:
| Lever | Realized | Weight | Weighted |
|---|---|---|---|
| Enterprise rate | $20,000 | 0.4 | $8,000 |
| Model swap | $21,249 | 0.7 | $14,874 |
| Batch API | $9,688 | 1.0 | $9,688 |
| Prompt cache | $5,452 | 0.7 | $3,816 |
| Conservative monthly | $36,378 |
Annualized: $436,536 — the lower bound of the range. Notice that the enterprise-rate lever, which is the biggest realized number, gets the steepest haircut because it's the one that depends most on negotiation outcome. That asymmetry is on purpose: a CFO talking to a board wants the conservative floor to discount the speculative line items the most. The high-confidence number (Batch API) passes through at 100%.
We render the range as the headline rather than burying the floor in a footnote. Both numbers carry the same visual weight, side by side. The conservative floor is the one a CFO defends to a board; the theoretical maximum is the one she takes into the negotiation with Anthropic procurement.
What this means for the catalog side
AI agent deployments themselves are a SaaS-spend lever — we covered the seven canonical cases in the AI-agents shortlist. The two products talk to each other. A company deploying Harvey AI for legal contract review is shifting some of its $80K Anthropic bill into Harvey's per-user pricing. Whether that's a net win depends on the Harvey contract terms, the legal-team seat count, and how much of the work was running on Opus when it could have run on Sonnet.
That's exactly the kind of trade-off both calculators surface side by side on a Growth+ dashboard. The seat compression product tells you which SaaS seats are wasted and which AI agent deployments unlock against your headcount. The AI Spend calculator tells you what fraction of your direct API bill is recoverable without changing your model choice. Most enterprises we've talked to have both problems — and the savings stack in the obvious direction: you take the API discounts first, then layer agent deployments on top.
The CFO bottom line
If your monthly Anthropic, OpenAI, or Google API spend is north of $50,000, you are leaving money on the table the size of a senior engineer's annual comp — minimum. The four numeric levers compose to between roughly 45% and 70% of the bill in most plausible scenarios. The exact number depends on your workload mix, your realtime share, and how much leverage your account team will admit you have.
Three things a CFO can do this week without engineering involvement:
1. Ask for the enterprise-tier conversation. At $50K+/mo, you're squarely in the bracket where the account manager has discretion. The 25% number we model is conservative; the published range goes to 40% for committed annual contracts. The downside risk is one meeting.
2. Audit your real-time share honestly. Most teams discover that 30–50% of what they assumed was real-time is actually overnight evals, bulk document processing, or summarization pipelines that nobody waits on. That's straight 50%-off-list money if engineering moves it to the Batch API. The Anthropic and OpenAI pricing pages both list it explicitly.
3. Check your prompt cache status. OpenAI customers may already be getting auto-discount on prompts over 1,024 tokens and not know it — check the dashboard. Anthropic customers running long shared prompts without cache_control breakpoints are paying 90% more on the cacheable input slice than they need to.
The methodology we're using to model all of this — every rate quoted against a vendor pricing page URL, every claim anchored to a literal quote, totals bounded by construction — is the same anti-fabrication trust contract that runs the SaaS catalog. A CFO can audit any number on the screen back to the source. That's the bar we hold for the seat-compression product, and it was non-negotiable when we scoped this one.
Try the AI Spend calculator — 15 seconds, no signup. Plug in your vendor, your monthly spend, your model mix, and the workload type. You'll have the range number — and the per-lever breakdown — before your next 1:1 with the CTO.
Find your savings number in 30 seconds.
No signup, no credit card. Get the number, screenshot it, and decide if your CFO needs to know about us.