The MAX-Overlap Rule: Why Two Agents Don't Compress 120%
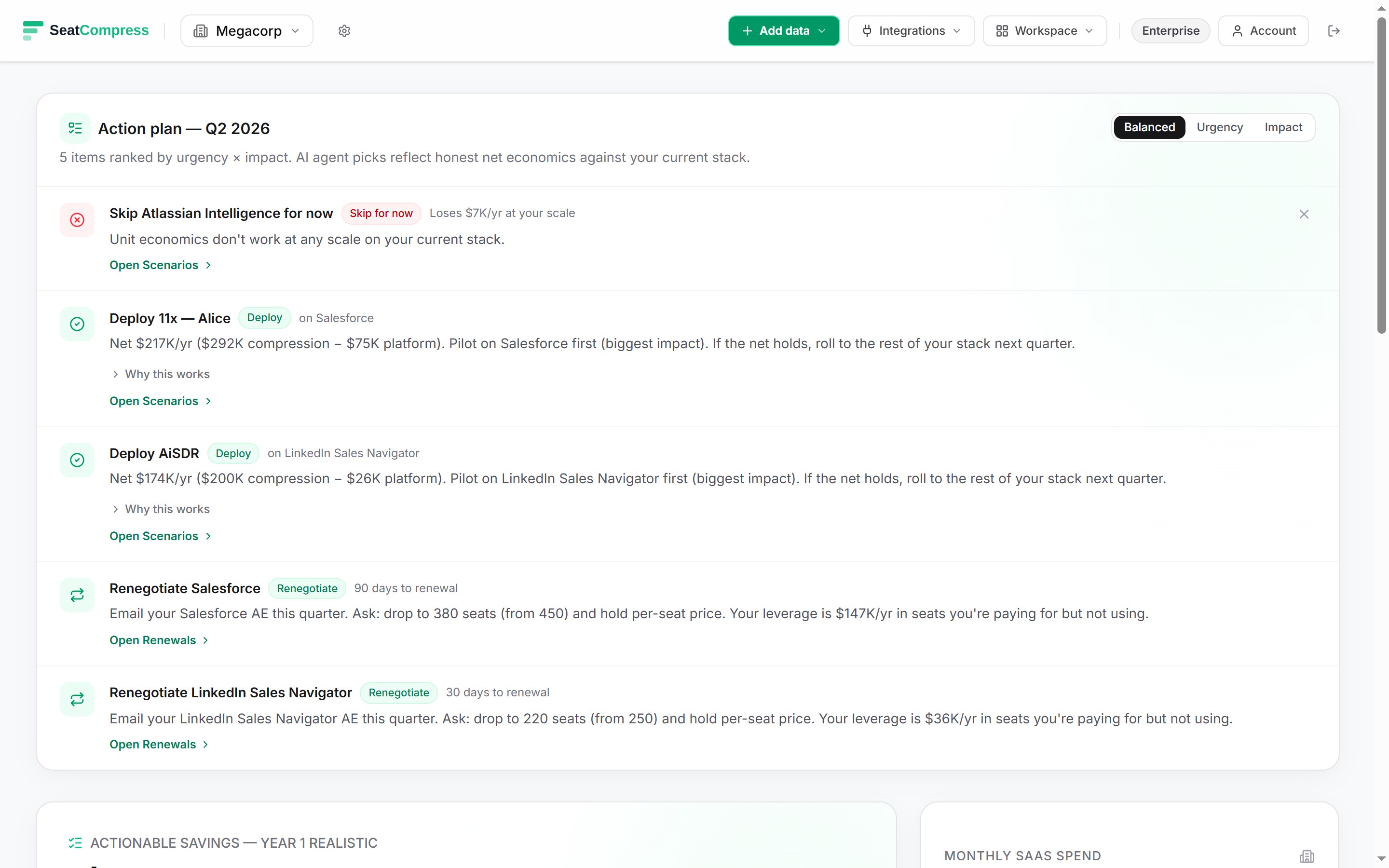
A vendor deck lands on your desk claiming three AI agents will compress your Zendesk seats by 185%. Decagon says 65%, Sierra says 60%, Ada says 60% — somebody summed them. The math is wrong, the deck is wrong, and the savings number on slide 12 is fiction. Two agents performing the same job on the same seat is double-counting, not double-savings. SeatCompress takes the highest single compressionPct per tool and discards the rest. Here's why, and what additive stacking does to a year-one ROI forecast at enterprise scale.
The bug in the deck: additive stacking on overlapping agents
The mistake almost always shows up in customer-support and engineering categories, because that's where vendor density is highest. Three production examples from our catalog:
Zendesk. Decagon 65%. Sierra 60%. Ada 60%. Intercom Fin 50%. Zendesk Advanced AI 40%. If you sum the first three, you get 185% compression on a tool that costs $115/seat/month. A 200-agent Zendesk org would supposedly need negative-one-hundred-seventy support reps. Add the next two and you're at 275%.
Intercom. Intercom Fin 60%. Decagon 60%. Sierra 55%. Ada 50%. Same story — four agents that all do tier-1 deflection on the same inbound queue.
GitHub Enterprise. Cursor Business 20%. GitHub Copilot Enterprise 15%. Cognition Devin 25%. Windsurf Teams 18%. Sourcegraph Cody 35%. Continue 25%. Six agents, all of them taking time off the same developer's coding workflow. Summed, they claim to compress a $21/seat tool by 138%.
The problem isn't that any single vendor is lying. Decagon really does deflect a meaningful share of tier-1 tickets in deployments where it owns the deflection workflow. Sierra really does deflect tickets where it owns the same workflow. The deception is in the addition. You don't run all three agents on the same ticket queue. You pick one, that one does the deflection, and the other two are doing nothing on those same tickets. The remaining tickets that escalate to humans aren't more deflectable just because Sierra is also installed — those tickets escalate because they need human judgment.
Why MAX is the only honest aggregation rule
Compression percentages aren't independent probabilities. They're estimates of "what share of seats this agent removes from this specific tool, assuming it owns the workflow." Two agents can't simultaneously own the same workflow.
The closest analogy from finance: you can't sum the recovery rates of two collection agencies you've sent the same delinquent invoice to. Whichever one collects, collects. The second one gets nothing on that invoice and a small percentage on the next one.
SeatCompress codifies this with one line in the analysis engine:
effectivePct = Math.max(...selectedAgents.map(a => a.compressionPctOnThisTool))
When no agents are selected, the engine falls back to tool.aiReplacementPotential — Zendesk's default is 0.60, Intercom's is 0.55, GitHub Enterprise's is 0.15. Those defaults are themselves anchored to a sourced cap; see why we source every compression percentage for the audit trail.
When agents are selected and any of them target a given tool, only the maximum compression value survives. Decagon (0.65) plus Sierra (0.60) plus Ada (0.60) on Zendesk resolves to 0.65 — the math the CFO can defend. Not 1.85, which is the math the CFO has to retract.
What 120% compression looks like in a year-one forecast
Pretend you run finance at a 12,000-employee SaaS company. Your support org has 180 Zendesk seats at $115/seat/month — annual contract value $248,400. A vendor team walks you through a deck:
- Decagon at 65% compression → save $161,460/yr
- Sierra at 60% compression → save $149,040/yr
- Ada at 60% compression → save $149,040/yr
- Combined savings claim: $459,540/yr
The contract value is $248,400. The deck just promised you $459,540 in savings on a $248,400 line item. The "savings" is 185% of the spend. If the CFO signs all three agents, the year-one P&L shows:
- Annual Zendesk spend: $248,400
- Decagon: $5K/mo × 12 = $60,000 subscription + $25,000 setup = $85,000
- Sierra: $6K/mo × 12 = $72,000 subscription + $35,000 setup = $107,000
- Ada: $4.5K/mo × 12 = $54,000 subscription + $15,000 implicit setup floor = $69,000
- Three-agent year-one cost: $186,000 subscription + $75,000 setup = $261,000
- "Savings" you actually realize: bounded by $248,400 — you can't compress a tool below zero
The deck's $459,540 line is mathematically impossible, but more importantly it triggers three concurrent integration projects to chase savings that one agent could deliver. The realized compression is capped at 65% of $248,400 = $161,460 theoretical, which the engine's 0.4 deploy realization factor pulls to $64,584 in year one. Year-one cash impact under the additive fantasy: negative $196,416 ($64,584 realized minus $261,000 spent). Decagon alone — $85,000 year-one cost — nets negative $20,416 in year one, then flips to positive $101,460 in year two when realization climbs to steady-state and setup is fully amortized.
The MAX rule isn't conservative accounting. It's the only rule consistent with the contract math.
Where overlap actually shows up: the audit pattern
When we audit a finance team's existing AI agent stack, the overlap pattern repeats across three categories. Counts below come from our production catalog as of June 2026:
Customer support deflection. Five agents — Decagon, Sierra, Ada, Intercom Fin, Zendesk Advanced AI — all target Zendesk and Intercom with overlapping deflection workflows. If a procurement team signed two of them ("Sierra for chat, Decagon for email") in separate quarters, the consolidated compression on Zendesk is the MAX, not the sum. A typical post-audit recommendation: cancel one, save the duplicate contract, take the same deflection.
Engineering AI assist. Cursor Business (20%) and GitHub Copilot Enterprise (15%) are the most common combo. The MAX is 20%, not 35%. Cognition Devin (25%) and Windsurf Teams (18%) overlap completely with Cursor. Sourcegraph Cody (35%) overlaps with all of them. A 30K-seat engineering org we modeled had four of these deployed concurrently — Cursor + Copilot + Devin + Cody summed to 95% on GitHub Enterprise in the procurement deck, but the engine resolved it to 35% (the MAX, from Cody). The other three agents were doing the same job on the same developer seat.
Sales prospecting. AiSDR (30% on Salesloft), 11x Alice (45% on Salesloft), Regie.ai (45% on Salesloft), Artisan Ava (63% on Salesloft). Four agents on the same outbound SDR seat. The MAX on Salesloft is 0.63 (Artisan Ava) — adding AiSDR, 11x Alice, and Regie.ai on top changes the per-tool compression by zero.
The audit catches it because the engine refuses to sum. The procurement decks don't, because each vendor's pitch is built in isolation.
When MAX doesn't apply: the orthogonal-workload exception
Two cases where stacking is legitimate, and the engine handles both correctly:
Different tools. Glean compresses Confluence 40% and Box 15%. Notion AI compresses Confluence 40% and Coda 30%. On Confluence the MAX rule resolves both to 40% (they're doing the same job). On Coda only Notion AI's 30% counts. On Box only Glean's 15% counts. The agents stack because the tools are different — not because the workflow on any single tool is additive.
Different cost models. A flat-fee agent like Decagon ($5K/mo) and a per-user agent like Zendesk Advanced AI ($50/seat) both compress Zendesk, but they're priced independently. The MAX rule still applies to the compression percentage — pick the higher one — but the cost-attribution side of the engine handles them separately. Decagon's flat fee is counted once across all tools it touches; Zendesk Advanced AI's per-seat cost scales with the agent's deployment size.
Sequential, not parallel, workflows. Intercom Fin handles deflection (60%); Sierra handles voice escalation on the 40% that didn't deflect. In principle these stack — different steps of the same ticket journey. In practice the catalog models both as primary deflection agents, so the engine applies MAX. If you want sequential stacking, you model it explicitly with two agents pointing at different sub-categories, which the schema doesn't support today. The conservative default — MAX — is the right call until the data model gets richer.
Worked example: 8,500-seat SaaS, full stack overlap audit
Take a SaaS company with 8,500 employees, $4.2M annual SaaS spend. Their support stack:
- Zendesk: 240 seats, 215 active, $27,600/mo, $331,200/yr
- Intercom: 90 seats, 78 active, $7,650/mo, $91,800/yr
Procurement signed Decagon ($5K/mo + $25K setup) in Q1 and Sierra ($6K/mo + $35K setup) in Q3. Total annual agent cost: $132,000 subscription ($60K Decagon + $72K Sierra) + $60,000 setup ($25K + $35K) = $192,000 year-one agent cost.
The additive (wrong) calculation procurement is running:
- Decagon on Zendesk 65% + Sierra on Zendesk 60% = 125% compression
- Decagon on Intercom 60% + Sierra on Intercom 55% = 115% compression
- Theoretical "savings": $331,200 × 1.0 + $91,800 × 1.0 = $423,000 (capped at 100% because even the bad math knows you can't go below zero)
- Net year-one: $423,000 − $192,000 = $231,000 "profit"
The MAX (correct) calculation the SeatCompress engine runs:
- Zendesk MAX = 0.65 (Decagon wins)
- Intercom MAX = 0.60 (Decagon wins on both, by 5pp)
- Theoretical compressible spend: $331,200 × 0.65 + $91,800 × 0.60 = $270,360/yr
- Year-1 realization factor (0.4 for deploys): $270,360 × 0.4 = $108,144 realized in year one
- Net year-one: $108,144 − $192,000 = negative $83,856
Year-one, the dual-agent stack is unprofitable. The CFO's correct move is to cancel Sierra (it adds zero compression — Decagon's max is higher on both tools), save the $72K annual subscription plus the $35K setup, and run with Decagon alone. Decagon-only year-one math: $108,144 realized savings minus $85,000 cost ($60K subscription + $25K setup) = positive $23,144. By year three, with full realization, Decagon delivers $270,360 in compression against $60K subscription cost — a 4.5× return.
The MAX rule doesn't kill the deal. It picks the right agent and cancels the redundant one. The CFO who runs additive math signs both, sees zero net savings, and concludes "AI agents don't work" — when the actual conclusion should be "I bought two agents to do one job." Run the same math on your stack in the calculator.
What the CFO does Monday morning
Three actions, in order:
-
Pull every AI agent contract signed in the last 18 months and list the SaaS tools each one claims to compress. Group by target tool. Any tool with two or more agents pointing at it is an overlap candidate.
-
For each overlap, take the MAX compression percentage and identify the redundant agent. The redundant agent isn't doing nothing — it's doing the same thing as the higher-compression agent on the same tool. Cancel the redundant subscription at the next renewal. The savings is the canceled subscription, not the "stacked compression" the original deck promised.
-
Rebuild the year-one forecast on the surviving agents using realization factors, not theoretical max. Our engine uses 0.4 for new agent deploys (steady-state ROI typically lands at 30-50% in year one, per LeanIX / McKinsey AI-adoption ramp curves). Theoretical compression × 0.4 × seat cost × 12 = the year-one number you put in the board deck. Apply the renegotiation-playbook framework to the surviving Zendesk / Intercom contracts at next renewal — the compression unlocks a credible seat-reduction ask.
The MAX rule isn't a quirk of how SeatCompress models AI agents. It's the only rule that produces a year-one number the CFO can defend in front of a board. Two agents don't compress 120%. They compress whatever the higher one compresses, and the second one is a subscription you can probably cancel.
Find your savings number in 30 seconds.
No signup, no credit card. Get the number, screenshot it, and decide if your CFO needs to know about us.